Columbia University Medical Center Publications
Columbia University Irving Medical Center (CUIMC) Publications is an institutional bibliography of scholarly journal articles. To be included in the bibliography, a journal article must be authored or co-authored by one or more Columbia University Irving Medical Center researchers. The bibliography draws on data from the PubMed, Web of Science, Scopus, and OpenAlex databases. I conceived of this project when trying to determine how many articles the Medical Center produces in a year. I then developed the project as a resource the Health Sciences Library offers to the Medical Center community.
The website allows users to search, filter, and export publication data. Users can also view summary data regarding the institution’s scholarly output.
Custom Drupal Theme
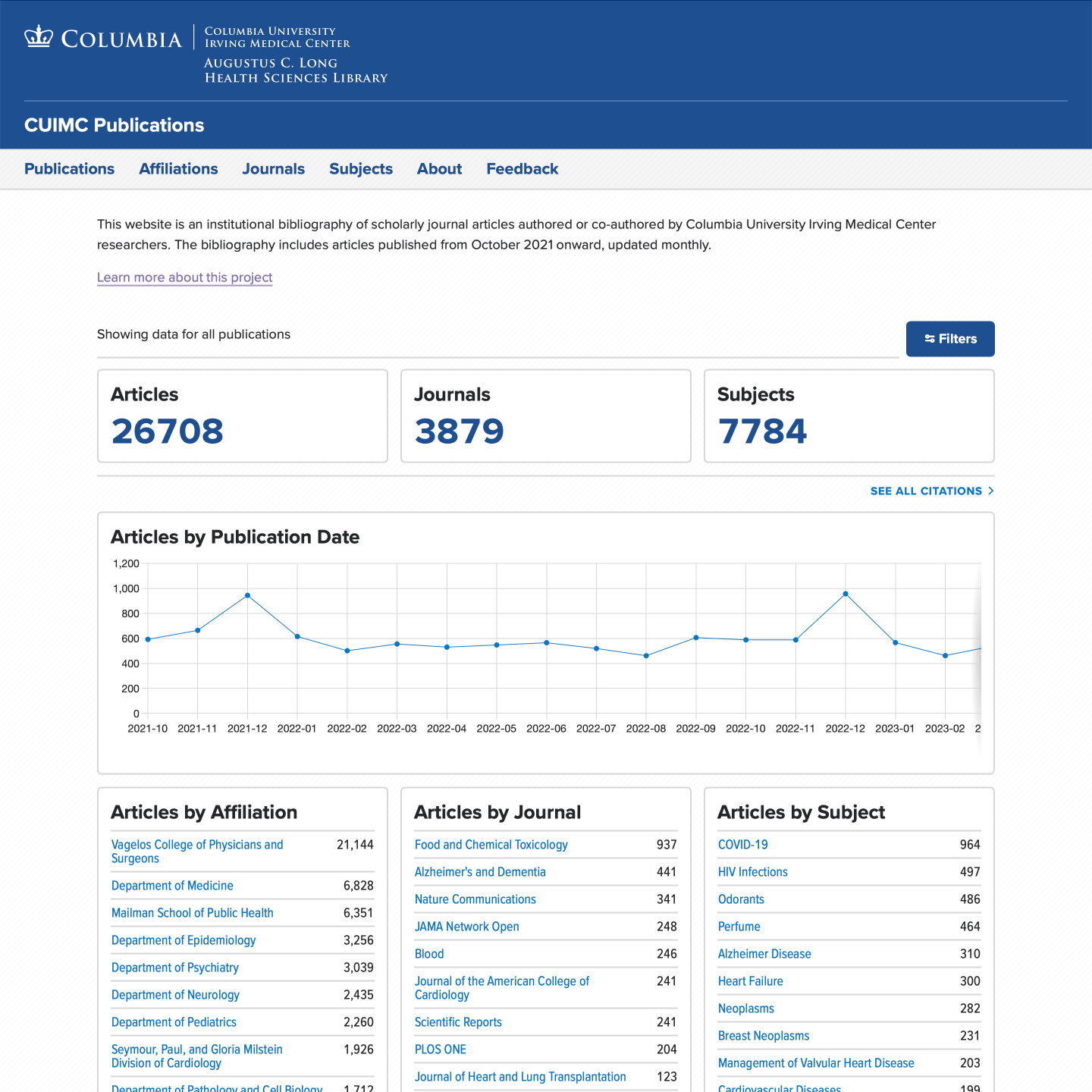
The Publications website is a lightly-decoupled Drupal website. The website home page shows a user-filterable display of aggregated publication data. Data is provided by custom endpoints to maximize performance. JavaScript interacts with the endpoints to render the front-end.
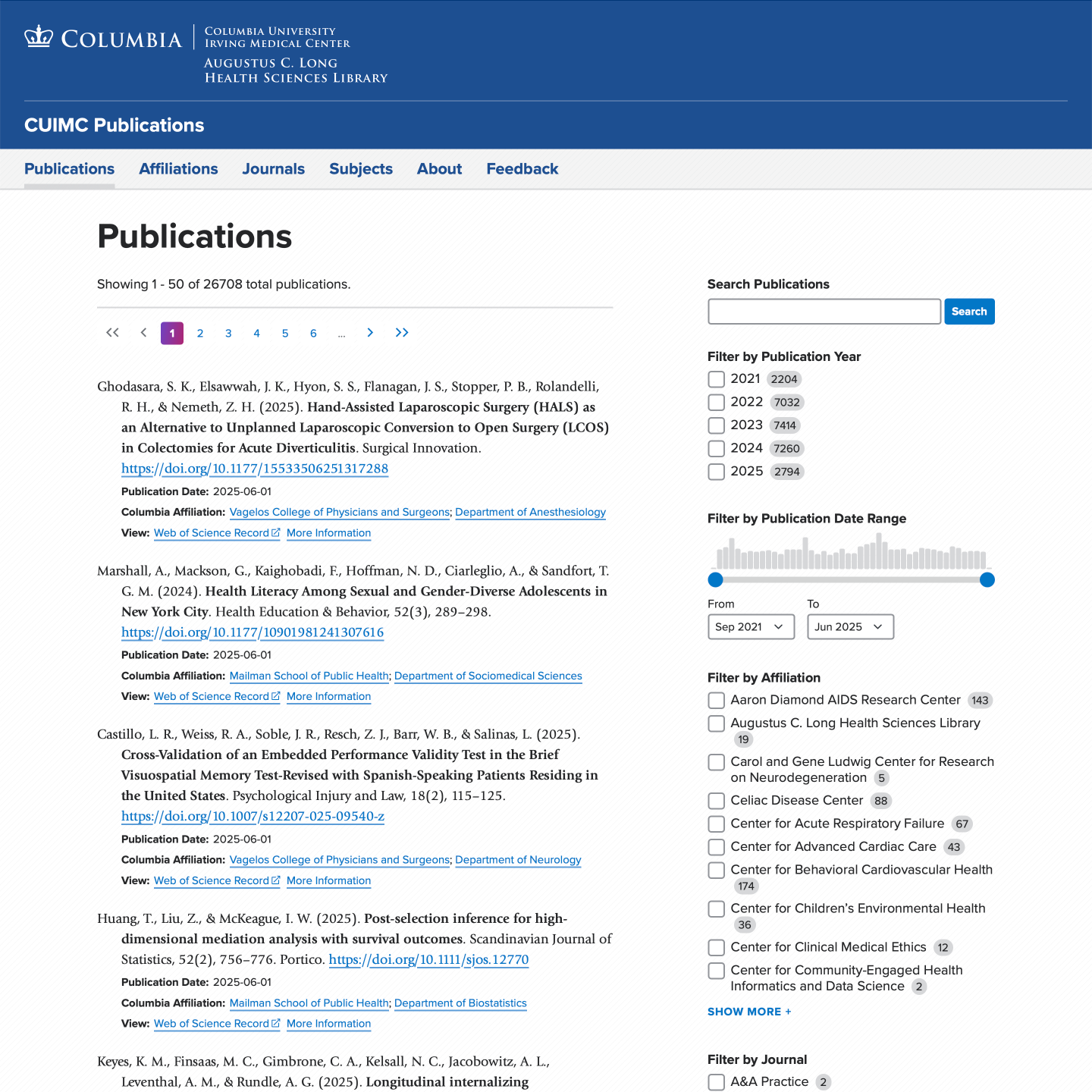
The main search interface is also decoupled with the help of the Search API Decoupled module. The module provides the search endpoints while the custom theme handles the data display and search facets. While the home page uses framework-free JavaScript, the search page front-end is built using the CSP-friendly variant of Alpine.js. This approach allowed me to design a robust search interface to handle facets that have hundreds of affiliation and journal options. It also allowed me to create facets that are not available using the Drupal Facets module.
Custom Drupal Module
Publications data is pulled from multiple sources, deduplicated, and tagged. I wrote a custom Drupal module to bulk import publication records and handle deduplication of publication and journal information. The majority of the import process is automated, allowing the database of publications to be maintained without significant staff resources.
Natural Language Processing
As publications are imported, they are tagged with school, department, and division affiliations. These affiliations are determined by author affiliation information provided by the authors to the publisher when the article is submitted for publication. Because the format of this affiliation information in not standardized, it is not reasonable to parse this information using string matching or regular expressions. It is the perfect use case for natural language processing.
Using the default spaCy NLP model I built a simple python web application that accepts a string of text and returns an array of identified organization names. This application is used to identify the school, department, and division names in the affiliation data and convert that information into affiliation tags applied to each publication.